Where will electronic music go?
Electronic music began with unusual sounds, step by step occupying the field of traditional music. Now there is no problem with tuning, variety of timbres or the processing of musical data. Electronics has reached real acoustic timbres whether it be the sounds of a Steinway or Jewish Harp, and the sound capabilities of modern music work stations considerably surpass the resources of a symphonic orchestra. But it is very difficult to use these resources with the usual methods for control of synthesis by a computer. The expressiveness of electronic music (whether it be performed on a synthesizer or by a computer MIDI sequencer) can not be compared to that of a live acoustic performance. Using even the best electronic equipment, no one can play convincing violin solos or virtuoso guitar accompaniment. Electronic music has many problems and the most vital are two:
- creating effective synthesis control methods;
- borrowing intoning experience of academic and traditional music culture, mastering music sound movement, achievement of expressiveness.
How does a musician play, and what underlies performance expressiveness? What does the computer have to learn?
Musicians consider that the essential principle of expression is in the gift of creativity and insight. That's true, but there are other not less important factors the expressive playing is impossible to be without. They are a design of an instrument, psychophysiology of a performer, general laws of intoning, performance devices worked out by practice of performance which are appropriate to a particular instrument, genre, manner. There is also a music language which is learned by a musician and is understandable to a listener. Music is played by rules sometimes quite plain sometimes subconscious for a musician, but absolutely unknown to a computer. And when we talk about expressive performance concerning computers it is too early to speak about gift and insight. First of all we must teach computers the basics of music language and rules of sound producing which it so easily breaks. But how to do that when a programmer's or an acoustic's question "How does a musician play?" can not be answered by either a conservatory professor or qualified psychologist. It is impossible to write computer programs based on impressions, emotions and words - an engineer needs logical expressions of performance, concrete algorithms, rules and digits.
How can we make musical scores expressive?
It's very simple! Computers have to be taught performance modeling. Notes and playing them are different things. Conceptually, a score is only a plan of performance. So a computer as well as a musician should study playing a score with a lot of nuances - volume changes, tuning, tempo and so on but not simply playing back music. These changes can be imagined as many parameter functions which transform source data - the electronic score. And how to receive such functions, that the effects are not casual but regular, that the computer performance approaches live playing? Obviously, we need a performance modeling program which is able to observe the rules of musical language as well as a live performer. We have been engaged in research of an expressiveness phenomenon for years and have created the performance modeling program Style Enhancer, which is now available to everyone.
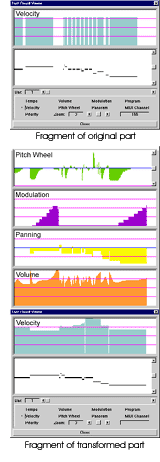
What working principles underlay Style Enhancer?
The main thing the performance modeling program has to do is analyze a musical part in an electronic score, recognizing certain Musical Objects in it (MO), i.e. notes and their combinations, and then to transform them. Style Enhancer copes with the task by recognizing and transforming MO by certain rules. The program sets up certain values in the Velocity, Start Time, Duration parameters, and automatically defines Pitch Wheel, Expression, Modulation and other functions.
How can we make sound-module sound differently, more expressive?
With the help of Style Enhancer - that is its direct purpose. Modern sound-modules faultlessly reproduce the sound of a chosen instrument, however when it comes to imitating a live performance the sound is not very similar. The fact is that playing on an acoustic instrument, as a rule, significantly varies the same sound. During processing of initial data Style Enhancer enters some functions of controllers into them for every note separately. It enters a set of nuances, even for one initial timbre, and thus considerably changes the sound-module output. To enter similar functions with the help of conventional Joystick, Bender Wheel, Breath, Pitch-to-MIDI is impossible. These functions are extremely difficult to enter in a sequencer even if you know how. Listen to a vocal part in "Oriental Bazaar" (bazar_se.mid), illustration of controller change function shown in the screen shot. Notice that part transformation with the help of the program has taken a few seconds. The most interesting results from a musical point of view are in tiny changes of note starts, fine drawings of volume curves, modulation, tuning, inherent to a live performance and which are impossible to reproduce by traditional methods. Listen to the acoustic guitar solo and flute, and also analyze functions of controllers in bossa_se.mid file, or look at guitar parts in "Siberian Dreams About Spain" (spain_se.mid) and I am sure you will agree with us.
How is Style Enhancer organized?
The basis of the program are Styles. The Styles consist of the various Rules & Tools - special modules, determining playing of characteristic Musical Objects. A certain combination of Rules & Tools, and their set-up, provides transformation of initial data and performance modeling on one or other instruments in this or another manner. The program has the Rules & Tools Library, from which you can choose necessary modules, whether you are creating a Style independently or if you just modify an existing one. The result of data transformation and all of the controller change functions entered by the program can be reviewed with the help of Tools Result Viewer, and statistical data - in Analyzer. The depth of processing for various parameters is set with the help of the Master Control panel, which allows a lot of variants of performance for the same Style.
How to work with the program and is it difficult to master it?
Working with Style Enhancer is very simple. You load into it an initial file (a track, a part) from any sequencer you work with. Choose a Style for processing, process initial data and listen to the result. With the help of Master Controls enhance the result in a few seconds per each variant and return file into sequencer. The basic operations such as Load, Save, Copy are the same as in the majority of the programs working under Windows.
Which performance variations can be applied, using SE?
The complete delivery version of Style Enhancer includes a Library of Styles for many families of instruments with each style performing in a different manner. The application of even one Style permits SE to receive a number of performance parameters which can apply to several instruments, modeling both traditional and exotic manners. If these many variations, received as changes to the initial parameters set up in the Master Control are not enough for you, additional opportunities are given to modify a Style, which does not require any special knowledge. You can also create your own Styles of performance. Just study the program and become acquainted with the principles of working with Rules & Tools in detail. Style Enhancer allows you to give new life to electronic timbres which don't have an expressed manner of behaviour in "design of the instrument - psychophysiology of the performer". Such experiments can be very interesting for composers and arrangers looking for an individual musical language.
How effective is the program?
Global, in the musical sense, transformation are made by SE in seconds. It changes parameters not of a single note but of a whole phrase or a complete part. Working with the program, an arranger spends more time on listening to the result of modeling, than on processing. And he works with the program almost like a live performer, giving commands such as: "play in another manner", "make brighter dynamic accents", "do not reduce tempo so obviously at the end of a phrase", and so on. Imagine how much more effective it is than playing a phrase or editing each note many times. What the program does is difficult to describe in words. It is better to listen to DEMO-files.
Who do you think the SE is addressed to?
In the first place - to composers, arrangers, professionals and amateurs, those who create music with the help of a sequencer program. There is no doubt about the fact that SE will free them from difficult routine jobs and will allow them to make even accessory parts of an arrangement more expressive . In some cases the program will also help save money that is spent on sound synthesizing equipment because the sound of available instruments will be greatly enhanced (usually, users don't know the real potential of their equipment). The most advanced musicians will be able to create their own styles of performing and actually expand their creative sphere. For composers and arrangers there is probably a considerable interest in creating styles of electronic voices that are not similar in kind to "psychophysiology - design of instrument". Such voices are not connected with a definite musical manner. Bright, characteristic musical images that are determined not only by the voice itself, but with its behavior in musical context. Thanks to SE the electronic voices can take a new life.
SE may also be useful for musicologists. The West-European musicology is not yet ready to formalize all that is out of frames of pitch and temporal coordinates. Musicologists easily work with interval correlations and temporal scale, but get stuck on expression, intoning, articulation, nuances of sound producing and turn to description language when we speak about such things. But there is no music without these "little nothings". Even excellent classical scores by themselves are the basis, the scheme only, and they require the proper performance. However the conformity to natural laws of performing remains the greatest mystery. Unpreparedness of traditional musicology to research the expression and performing problem is revealed especially clearly when it concerns the folklore material. And indeed, what can the West-European school tell about a piece performed on the Vargan, where the change of the pitch is completely absent (the main tone does not change in principal), and musical content is in variations of spectrum and temporal organization...
With the usage of SE it is possible to model an extremely wide spectrum of musical intonations and in this matter they will not be something ephemeral. Quite severe formal parameters will be suitable for them. Maybe modeling of the performance, where a musician plays the role of an expert will prove to be a more effective method of revealing the conformity of natural laws in expressive performing than the method of traditional analysis?
However paradoxical it is, Style Enhancer could be used for training a performer. On the one hand it is possible to show him the real things which are responsible for expression, the differences between notes as signs on paper and realtime performance. It is known that the use of visual methods in the process of learning stands very far from being an unnecessary factor, but the traditional method (Do as I do) brings many restrictions to it. When a teacher changes parameters in SE modeling of the performance he can show his pupil a considerably greater spectrum of possible interpretations. In this case it is not difficult to sharpen one or another typical musical phenomenon showing what will happen when the rules are observed or vice versa and so on. It is quite possible, and the results could be very interesting, if some performance models were transferred to a living performer. Why not, composers and artists don't refuse machine, combinative variants of compositions as material for creative interpretation, you know...
Alexei Ustinov, March, 1996
The article is prepared in March 1996 in connection with release of Style Enhancer 1.0, is edited in February 1999 by Les Gorven (The MIDI Studio Consortium http://MIDIstudio.com), also has received fine final edition in August 1999 by James Christensen (Technical Writer, Cakewalk.)